
Fault tolerance patterns for microservices
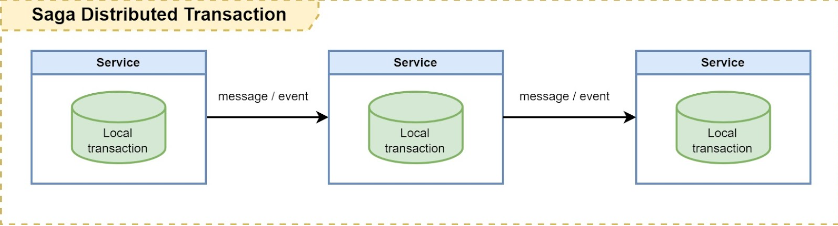
Did you know that in distributed systems, sometimes things just don't work the way they should because of failures. Hence, you must bear in mind that failure is everywhere and think differently about how to solve your problems.


0
Leave a comment
Submit with
Comments (0)




OTHER ARTICLES FROM DO TRAN

Logging And Structured Logging With Serilog The Definitive Guide
17 May 2024
6 mins read

Introduction to TPL Dataflow in C#
29 Feb 2024
7 mins read

Implement Producer/Consumer patterns using Channel in C#
17 Jul 2023
6 mins read

Json Web Token Using C#?
22 Jun 2023
5 mins read

How string works in c#
29 Mar 2023
7 mins read













