Implement Distributed Lock For a Microservices Software System
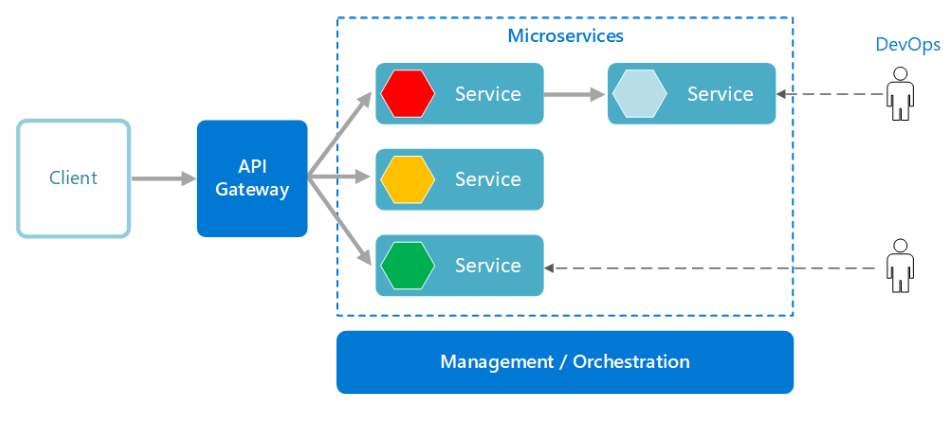
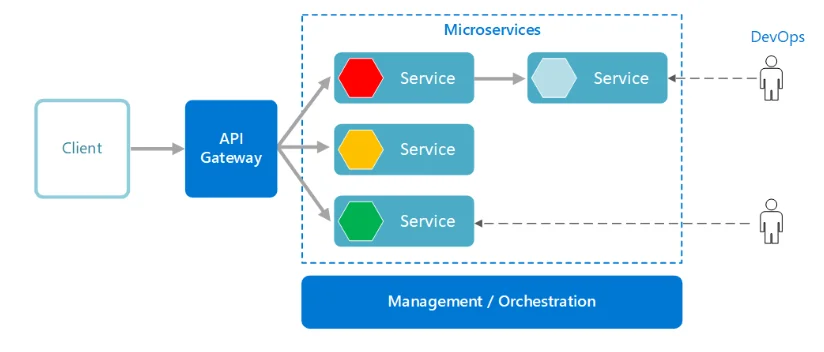
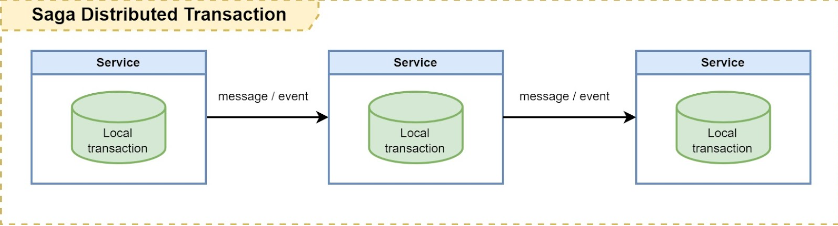
Are you facing problems with data consistency in a highly concurrent environment? Are you looking for a way to limit and synchronize access to a shared resource across services in a distributed system? Let's see how a distributed lock can help in this situation.


0
Leave a comment
Submit with
Comments (0)